|
 |
|
| |
|
|
|
1. Теория 2. Практика 2.1 Анализ звука в Sound Forge. 2.2 Редактирование звука в Sound Forge. 2.4 Увеличение уровня. Клиппинг. Нормалайз и эквалайз. 2.5 Использование RazorLame для сжатия в MP3. 2.6 Использование mp3Trim для "резки хвостов". 3. Ссылки Для начала придётся сделать маленькое отступление и чуть-чуть углубиться в теорию звука. Я, правда, не дипломированный звукорежиссёр и не инженер по звуковоспроизводящему оборудованию, но успел немножко поработать на телевидении и радио, кое-чего нахватался (а если заглянет к нам на сайт настоящий специалист - милости просим! - пусть поправит меня, если я в чём не прав, или сам напишет статью о звуке. Будем рады!) Итак, почему один звук мы слышим как более тихий, а другой - как более громкий? Если звук один и тот же (например, одна и та же музыкальная запись) - тут всё более-менее просто. Есть такая единица громкости децибел, дБ (единица, кстати, не линейная, а логарифмическая, что важно! но об этом чуть позже). Больше дБ - выше громкость. Именно эту громкость мы меняем, поворачивая ручку громкости на нашей аудиоаппаратуре.
Более-менее научное определение гласит, что "Громкость - это кажущаяся сила звука". Именно кажущаяся! Дело в том, что мы с вами - живые существа, а все органы чувств всех живых существ реагируют на раздражители (в том числе - на звук) не линейно, а логарифмически, подчиняясь небезызвестному психо-физическому закону Вебера-Фехнера, согласно которому изменение ощущения пропорционально логарифму изменения воздействия. Проще говоря, для того, чтобы звук показался нам громче вдвое, его мощность надо увеличить далеко не вдвое! Насколько конкретно - зависит от исходного уровня.
Но любой звук имеет определённый спектр или диапазон частот, и вот тут нас поджидают некоторые сложности. Во-первых, наше восприятие громкости звука зависит от частоты оного. То есть, звуки, равные по амплитуде сигнала, но разные по частоте, мы воспринимаем неодинаково! Наш слух "настроен" на определённые частоты, и звук на этих частотах мы субъективно воспринимаем как более громкий. Максимальна чувствительность в районе 1 - 4 кГц, (это основные тона человеческого голоса). Значение уровня звука и субъективно слышимой громкости совпадают только на частоте 1000 Гц, а дальше чувствительность сильно падает в обе стороны. На основании исследований человеческого слуха были построены графики, которые известны каждому звукорежиссеру как кривые равной громкости. Практический же вывод из этого следующий: хочешь сделать громче - поднимай средние частоты!
Второй момент, важный для нас - особенности воспроизведения звука конкретным звуковым устройством. Нас ведь интересует воспроизведение звука динамиками мобильного телефона, а именно Motorola E398. К сожалению, я не располагаю оборудованием, необходимым для детального исследования характеристик звукового тракта аппарата, но кое-какие выводы можно сделать и косвенно - исходя из субъективных оценок "громкости" и "звонкости" конкретных мелодий - то есть, слушаем в телефоне мелодии, а затем те, что звучали лучше (громче) других - подвергаем анализу. Но тут мы уже подходим к практической стороне дела. Я пользуюсь программой Sound Forge 5-й версии, с русским интерфейсом (вполне вероятно, что у вас будет установлена более свежая версия, но особой разницы нет). Sound Forge (далее по тексту - SF) для работы со звуком - незаменимый инструмент, такой же, как Photoshop для работы с графикой. Это стандарт для компьютерной обработки звука.
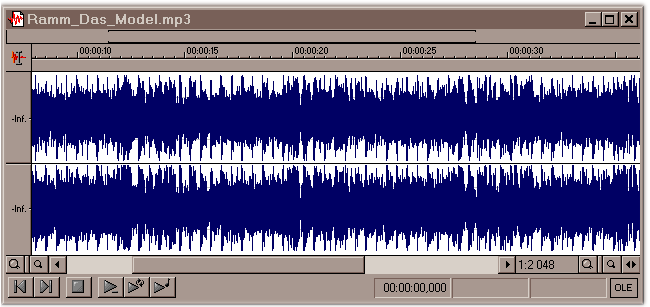
Первая - Rammstein - Das Model (667kb, 112 kbps, stereo). Вот как она выглядит на диаграмме в SF.
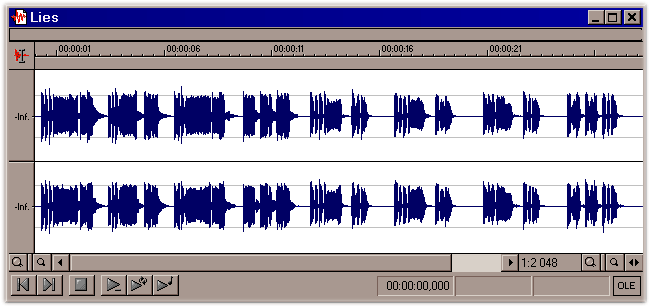
Вторая - Kusturica - Lies (444kb, 128 kbps, stereo). Вот как она выглядит на диаграмме в SF.
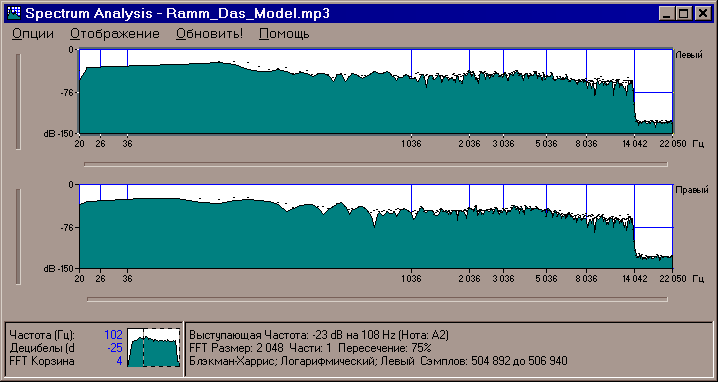
На первый взгляд, можно сделать вывод, что первая фонограмма должна звучать громче - ведь у неё больше амплитуда звукового сигнала. Ан нет! Достаточно загрузить обе в телефон, чтобы убедиться - одинокая дудка Кустурицы перебивает плотные децибелы "Раммштайна"! Загадка разъясняется при взгляде на спектрограммы обеих записей. Вот спектральный анализ первой:
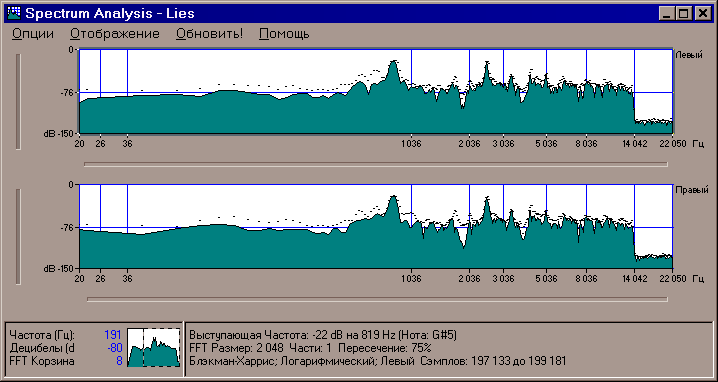
...а вот наглядный спектр второй:
Мы видим, что звук нашей дудки имеет выраженные "горбы" в районе около 1 и 2,5 килогерц. Это - область, в которой наш слух наиболее чувствителен. Звук же "Раммштайна", хоть он и более громкий в целом, не имеет заметного "подъёма" на средних частотах. Децибелов-то там достаточно, да "размазаны" они по всему слышимому спектру! Возможно, на концертной площадке этот факт имел бы преимущество - но не в телефоне с его крохотными динамиками.
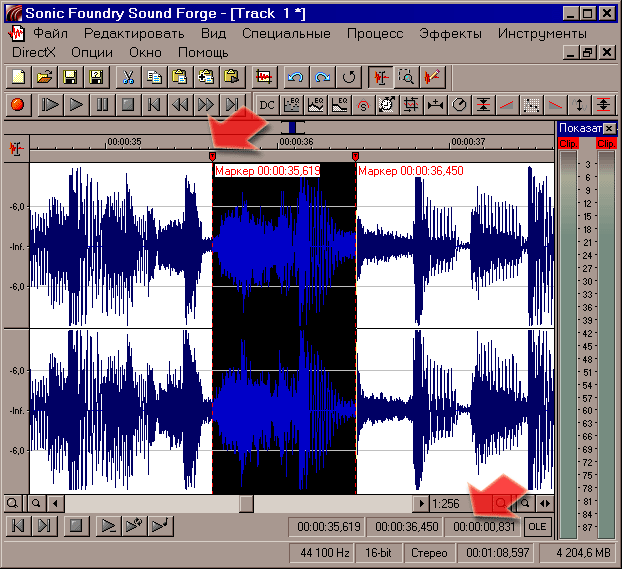
Наш вывод: в качестве звонка на телефоне будет громче звучать та запись, в которой преобладают средние частоты. Такая запись во-первых субъективно воспринимается как более громкая, а во вторых более приспособлена для воспроизведения через динамики нашего мобильника. Перейдём теперь непосредственно к редактированию фонограмм. Когда я выше говорил об удобстве SF, прежде всего имелось в виду удобство выделения нужного фрагмента фонограммы. Вы всё ещё выделяете мышью? Тогда мы идём к вам! ;) Забудьте о неудобном манипуляторе - научитесь пользоваться волшебной клавишей "M" (в английской раскладке, от слова marker). Клавишей "пробел" запускаем воспроизведение, а дослушав до нужного места нажатием клавиши "Enter" останавливаем его (в этом случае курсор внутри фонограммы не вернётся в исходную позицию, а остановится на том месте, до которого мы дослушали). Более точную подгонку позиции можно осуществить "стрелками" вправо и влево, иногда для этого могут потребоваться и масштабирование "стрелками" вверх и вниз (или колесиком мышки - вот и она пригодилась!). Затем нажатием "M" мы устанавливаем на этом месте маркер (помечен стрелкой на скриншоте). Так же поступаем и в конце нужного нам отрезка. Теперь выделить участок между двумя маркерами можно просто двойным щелчком мышки.
Программа покажет нам в статусной строке продолжительность выделенного фрагмента (показано стрелкой). Не стану подробно останавливаться на остальных приёмах редактирования - они очевидны (Control+C, Control+V, Delete). Предостерегу только от случайного повреждения ваших исходных фонограмм. Я и сам несколько раз портил свои архивные записи, по забывчивости сохраняя уже отрезанный фрагмент. Чтобы этого не случилось - не отрезайте ничего в исходном файле! Просто скопируйте нужный фрагмент в буфер обмена (очень удобно делать это из контекстного меню, по правой кнопке мышки), затем закройте исходный файл, и выберите меню "Редактировать". В отсутствии открытых файлов там будет единственная нужная вам опция: "Вставить в новый" (если есть открытые файлы, эта опция находится в меню "Редактировать" - "Особая вставка"). Чуть-чуть забегая вперёд предупрежу вас ещё вот о чём - если вам нужны промежуточные результаты работы, сохраняйте их в формат WAV (PCM, 44100 Hz, 16-bit, стерео или моно - в зависимости от исходного файла). Не сжимайте записи в формат MP3, пока работаете в SF! Работать с WAV быстрее, и результат качественнее.
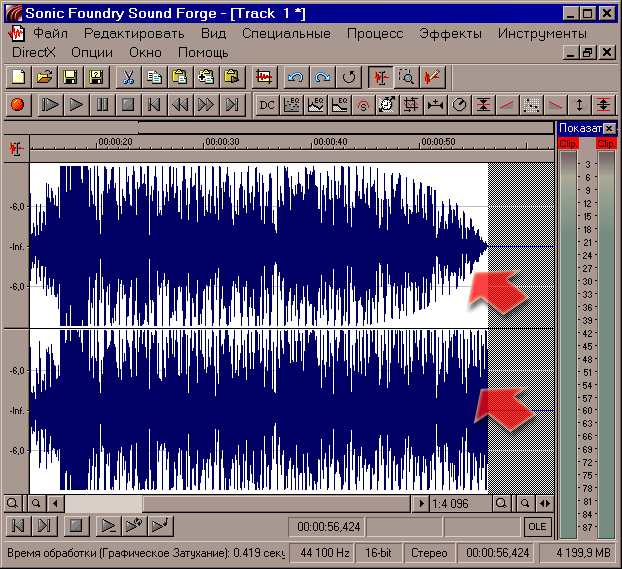
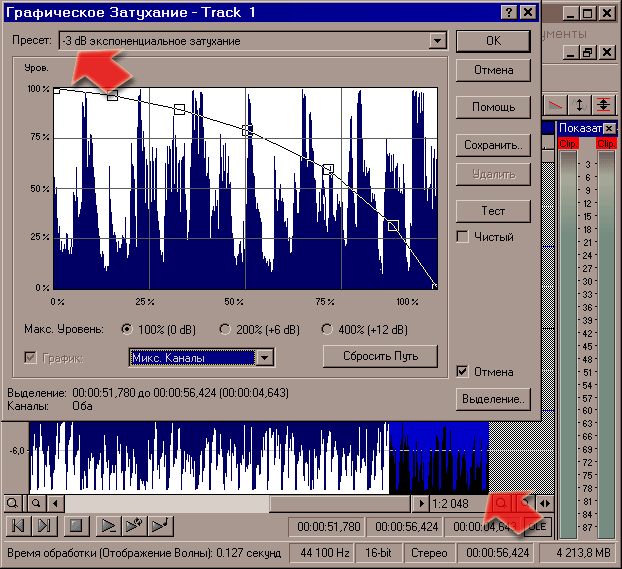
Взгляните на скриншот - разница между левым и правым каналами видна сразу. В левом канале уже сделан "фэйд-аут", то есть плавный вывод звука "на ноль". В SF есть несколько инструментов для фэйда, я обычно использую "графическое затухание" (в меню "Процесс" - "Затухание"). Графическое лучше линейного по той простой причине, что громкость звука мы воспринимаем по логарифму, о чём говорилось в теоретической части статьи.
Вот диалоговое окно, в котором вы можете выбирать разные виды графика затухания. Можете даже нарисовать свой собственный график. Экспериментируйте! "Ввод" звука, или "фейд-ин" осуществляется также.
Собственно
уровень меняется в меню "Процесс"
- "Громкость", но удобнее
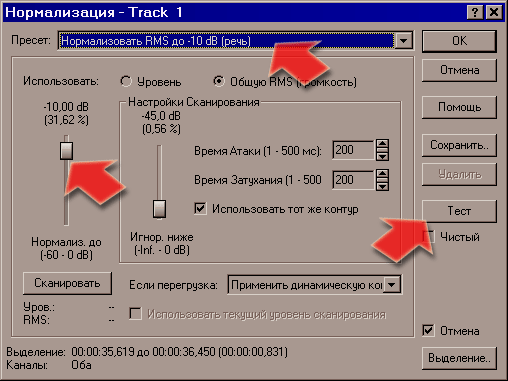
пользоваться меню "Процесс" - "Нормализация".
Нормалайз, в отличие от уровня, работает
не "абсолютно", но "относительно"
(прошу прощения за расплывчатые
формулировки - я всё же не
профессиональный звукорежиссёр).
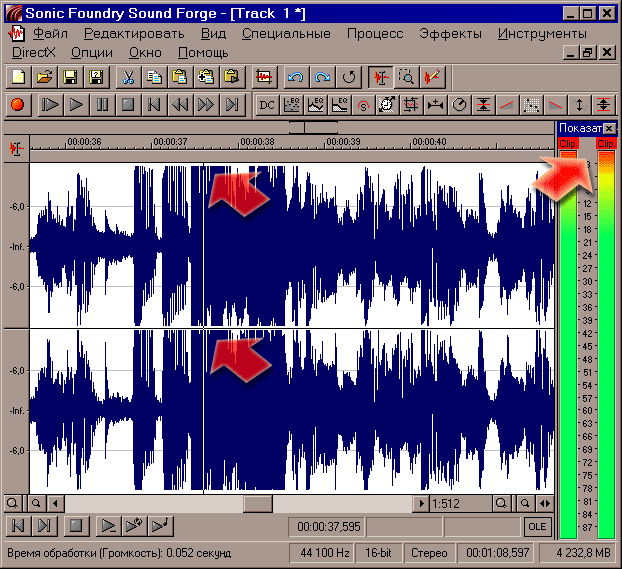
Нормалайз в SF имеет несколько пресетов: -16 дБ (музыка), -10 дБ (речь) и -6 дБ (оч. громко). Впрочем, и к громкости надо подходить с умом. Как говорится у Гоблина - "Без фанатизма!" ;) Взгляните на скриншот ниже: по нему можно сразу сказать, что здесь кто-то перестарался с уровнем сигнала!
Об этом свидетельствуют и красные индикаторы клиппинга, и характерная "плоская" форма графика (всё помечено стрелками). Для самых дотошных - примечание мелким шрифтом. Для остальных же просто скажу - не надо насиловать звук. Громче всё равно не станет, а вот искажения появятся. Лучше перечитайте ещё раз теоретическую часть и вспомните, что у нас с вами, помимо уровня сигнала, есть другие возможности сделать звук субъективно громче. Но об этом - дальше.
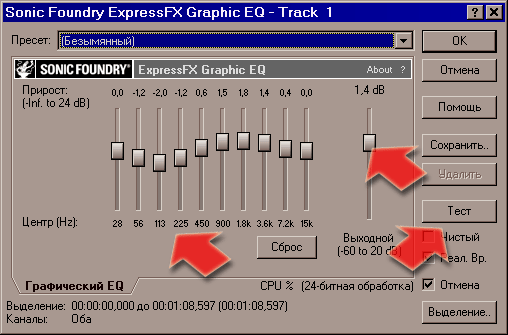
Что же нам ещё сделать для увеличения субъективной громкости нашего "звоночка"? А давайте вспомним о том, что звуки на частоте 1-4 килогерца воспринимаются как более громкие, и используем эквалайзер. В случае нашего любимого мобильного мультимедийного медиа-центра E398, нам приходится также думать ещё и о проблеме дребезжания "сабвуфера". Опытным путём установлено, что резонансная частота нашего "саба" находится в районе 160 Герц. А "дребезжание - ни что иное, как резонанс. Как с ним бороться? Да просто убавить, "придавить" эту конкретную частоту (на самом деле, "придавить" точно 160 Герц нам никак не удастся, поэтому действовать будем с запасом. За один проход эквалайзера мы можем "убить двух зайцев" - и придавить басы, и поднять средние частоты. Единой рекомендации - на сколько убавлять/прибавлять конкретные диапазоны частот - я дать, конечно, не могу. Всё зависит от исходного материала. Поэтому двигайте ползунки и нажимайте кнопочку "Test" для контроля того, что получается. Я обычно этим не ограничиваюсь - и обязательно прослушиваю всё, что получилось, непосредственно в мобильнике. Нередко приходится возвращаться к промежуточным файлам, и пробовать обработку снова, с иными значениями. (Именно по этой причине я настоятельно рекомендовал вам сохранять промежуточные результаты в формате WAV!) "Обычный" эквалайзер SF находится в меню "Процесс". Но мне больше нравится другой, установленный в виде отдельного плагина. Каким будете пользоваться вы - вопрос привычек и удобств.
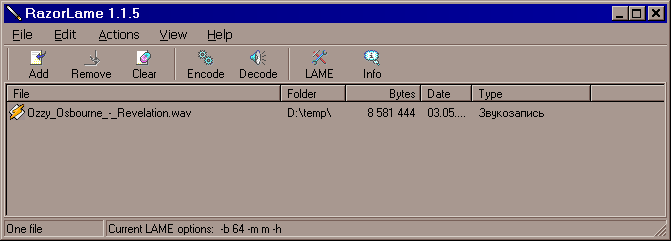
Примерно так это выглядит в работе. Стрелочками помечены наиболее важные для нас "нижние" частоты, кнопка прослушивания и ещё - заметьте это удобство - отдельно стоящий ползунок громкости. Он позволяет нам не обращаться лишний раз к "нормализации" нашего звука, а просто и быстро изменить общий уровень громкости. Иногда это удобно. Как уже упоминалось выше, результат я всегда сохраняю в WAV. Но для телефона этот формат совершенно не годится (ещё бы, примерно 10 мегабайт на минуту звучания!). Посему, добившись желаемого звучания, нам предстоит полученный файл сжать в MP3. Делать это удобнее всего при помощи программы RazorLame, а не из самого SF. Дело в том, что в SF для сжатия в MP3 используется лицензионный кодек от Fraunhofer IIS, а есть информация о том, что этот кодек не слишком хорош как раз на низких битрейтах (а нам-то как раз они наиболее интересны). К тому же в RazorLame и настройки удобны, и сама программка проста и приятна (бесплатна, не требует инсталляции, легко настраивается, быстро работает). К тому же, приучившись "жать" музыку в ней вы не будете рисковать испортить звучание, сжимая промежуточные файлы в SF - впрочем, я не настаиваю, пользуйтесь тем, чем лично вам удобно. Я просто рассказываю вам о своих методах. Итак, вы скачали архив с программой и распаковали его в удобную для вас папку. Создали ярлык к исполняемому файлу на "Рабочем столе" - или где вам удобно. Теперь минимум настроек, которые надо сделать лишь один раз.
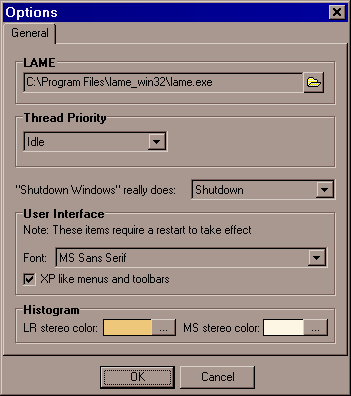
В меню "Edit" есть пункты "Options" и "LAME Options". Первый - это настройки программы. Там нужно указать только путь к самому файлу кодека lame.exe - он поставляется в архиве вместе с программой (по сути RazorLame - лишь графический интерфейс к этому кодеку и его настройкам).
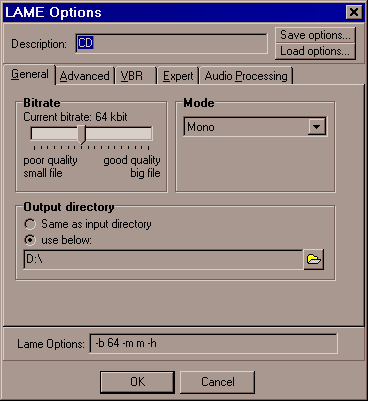
Указали путь? ОК. Теперь настроим сам кодек. Для этого загрузим из кучи пресетов, поставляемых вместе с программой, пресет "CD" (найдём его под кнопкой "Load options"). Изменим параметры так, как показано на рисунке: ползунок битрейта установим на "64 kbit", а режим ("Mode") - выберем моно.
Убедимся, что в строке опций (внизу окна) у нас стоит именно "-b 64 -m m -h". В принципе, и руками можно написать.
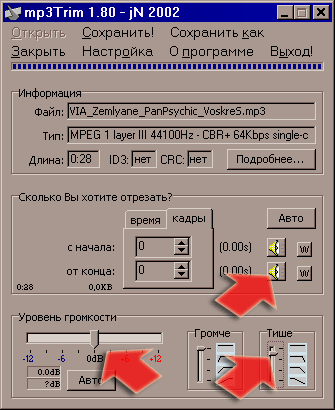
Порой возникает необходимость просто отрезать "хвостик" уже имеющегося "звоночка". Такое часто бывает, если вы не сами резали мелодии, а скачали уже готовые "нарезки" хотя бы вот из этой знаменитой ветки этого знаменитого форума. Оригинальных рингтонов там много, но большинство "резчиков-любителей" пользуются тем софтом, что есть под руками (очень часто - программой mp3DirectCut), и в результате их "творения" часто страдают "болезнью куцых хвостов" ;) Привести "хвосты" в порядок нам поможет крохотная программка mp3Trim (всего 210 kb). Она также попадает в категорию любимых мною крохотулек (без инсталляции, без регистрации, да ещё и русский интерфейс). Работать с ней - проще простого: открываем нужный файл (увы, drag&drop не поддерживается!), нажимаем на нижний "динамик", чтобы прослушать концовку - тот самый куцый хвост! (а верхний "динамик" - прослушка начала файла. Под загадочными надписями "Громче" и "Тише" скрываются знакомые нам "фейд-ин" и "фейд-аут" (вот они, издержки локализации! по-английски куда понятнее!). Ползунки регулируют крутизну/пологость фейда.
Заметьте также, что эта программа, при всей своей крохотности умеет менять уровень громкости и даже делать нормалайз (кнопка "Авто" под ползунком уровня). Особо хочется отметить, что, подобно mp3DirectCut эта программка относится к классу "фреймовых" редакторов, которые не нуждаются в распаковке сжатого в MP3 звука! Таким образом, ею можно пользоваться без боязни ещё ухудшить качество уже сжатого звука. Недостаток у mp3Trim только один - ограничение на размер обрабатываемого файла. Для наших с вами "звоночков" это совершенно некритично. Но вот если захотите, допустим, обработать целую оперу - придётся покупать Pro-версию. Краткая теория звука (первая часть) Краткая теория звука (продолжение) © Tester 2005 |